Uber如何做到傑出的資料品質
導讀
在討論數據品質(Data Quality)前,我們往往是看著別人提出的品質指標,並且想方設法的套進自己的組織內,但這樣的流程是不對的。即便是Uber這種已經建立完整監控數據品質架構的公司,也不是一步登天的。
事實上,Uber也經過很長一段時間去摸索該如何設定指標以及如何建立架構,因此我們看到的一套完整架構也是根據組織內部的需要逐步調整最後才能貼合現實。
翻譯自:Uber Tech Blog
Uber在全球市場能有效維運線上環境歸功於數以百計的服務、機器學習模型和成千上萬的資料集。當成長突飛猛進時,Uber透過維護數據品質來提供優秀的商業決策。若是沒有數據品質保證,下游的服務和機器學習模型成效會顯著下降,這需要很多額外操作才有辦法回填那些髒資料。最糟糕的是,這有可能會根本無法被察覺,而變成隱形殺手。
這促使Uber建立一個數據品質平台(UDQ)來監控這些問題。為了資料品質能夠達標,UDQ支援超過2000個重要資料集,被且偵測到超過90%的資料問題。這篇文章會描述Uber怎麼定義數據品質標準,以及如何整合工作流程以便良好維運。
Case Study
身為一個數據驅動公司,Uber透過海量資料來做商業決策。舉例來說,行程的制定仰賴多個參數:區域、天氣、事件等,其中最決定性的兩個參數是需求量和供給量。
需求量和供給量的資料集是來自移動裝置經由實時管線輸入的。任何系統層面的問題(管線延遲、App推送錯誤等)都會導致數據不完整或不精確,這就會導致行程計算錯誤進而影響整個市場。因此,能夠主動捕捉這樣的錯誤就非常重要。
要能正確在海量資料集下找到品質問題,最直覺的作法是預先定義一連串的驗證(測試)規則,接著定期執行測試來確認數據品質有沒有達標(SLA)。對於供給量的資料集,我們可以預先定義如下測試,系統會根據設定好的頻率定期發動,若是測試失敗就會送出告警。
表格和公式就不翻了,不難看懂
| Description | Mocked Queries | Mocked Assertion |
|---|---|---|
| Daily supply data count should be no less than 10,000 | SELECT COUNT(*) FROM supply WHERE datestr = CURRENT_DATE; | query_value > 10,000 |
| Supply data count should be consistent week over week | SELECT COUNT(*) FROM supply WHERE datestr = CURRENT_DATE; | ABS(query0_value – query1_value) / query1_value < 1% |
| SELECT COUNT(*) FROM supply WHERE datestr = DATE_ADD(‘day’, -7, CURRENT_DATE); |
UDQ就是根據這樣的基礎搭建的。但是,為了要能更好的維運數千張資料表,Uber必須考慮以下限制:
- 各團隊間沒有一個標準的數據品質測量方法。
- 建立一個資料集的測試需要很多手工,一次上傳大量資料表時難度又更高。
- 除了數據品質測試,還需要一個自動化且標準化的告警機制,但又不能誤報。
- 在問題被偵測到後,光只有告警是不夠的,還需要有個好的流程能確保所有問題都被解決。
- 為了測量成效,需要對於成功條件的清楚定義,並且要能簡單的計算成效指標。
- 身為一個全公司通用的平台,UDQ必須要能整合其他的數據平台。
Data Quality Standardization
為了設計Uber數據品質的基準,Uber搜集來自資料生產者和消費者的回饋,並且分析過去幾年意外事件的主因。有些常見的問題包含:資料抵達延遲、資料丟失或重複、跨資料中心的不一致或資料不正確等。根據這些,Uber訂了一些分類來涵蓋所有品質問題。
- 新鮮度:當資料已經99.9%完整時的延遲時間。
- 完整性:資料行的完整比例,這需要和上游資料及比對。
- 重複性:資料行中主鍵重複的比例。
- 跨資料中心的一致性:比對源資料中心和目的資料中心資料集的資料遺失比例。
- 其他:根據商業邏輯的測試比對都屬於這個分類。
每一個測試分類都定義了一些計算公式。
| 分類 | 先決條件 | 測試公式 |
|---|---|---|
| 新鮮度 | 已經具備完整性指標 | current_ts – latest_ts where data is 99.9% complete < freshnessSLA |
| 完整性 | 上下游資料集是一對一關係 | downstream_row_count / upstream_row_count > completenessSLA |
| 完整性(抽樣) | 上游資料集抽樣寫入Hive | sampled_row_count_in_hive / total_sampled_row_count > completenessSLA |
| 重複性 | 資料生產者有提供主鍵 | 1 – primary_key_count / total_row_count < duplicatesSLA |
| 跨資料中心一致性 | N/A | min(row_count, row_count_other_dc) / row_count > consistencySLA |
| 跨資料中心一致性(抽樣) | 用Bloom-Filter抽樣兩邊的資料中心 | intersection(primary_key_count, primary_key_count_other_dc) / primary_key_count > consistencySLA |
| 其他 | N/A | 使用者建立客製化的測試,沒有標準公式。 |
Data Quality Platform Architecture
數據品質架構包含以下元件:測試執行引擎(Test Execute Engine)、測試產生器(Test Generator)、告警產生器(Alert Generator)、意外管理者(Incident Manager)、指標回報器(Metric Reporter)和呈現工具(Consumption Tools)。整個架構的核心是測試執行引擎,會根據各種需求執行測試、檢查結果並將結果存入資料庫。其餘元件則是圍繞著測試執行引擎,完成整個數據品質的生命週期。
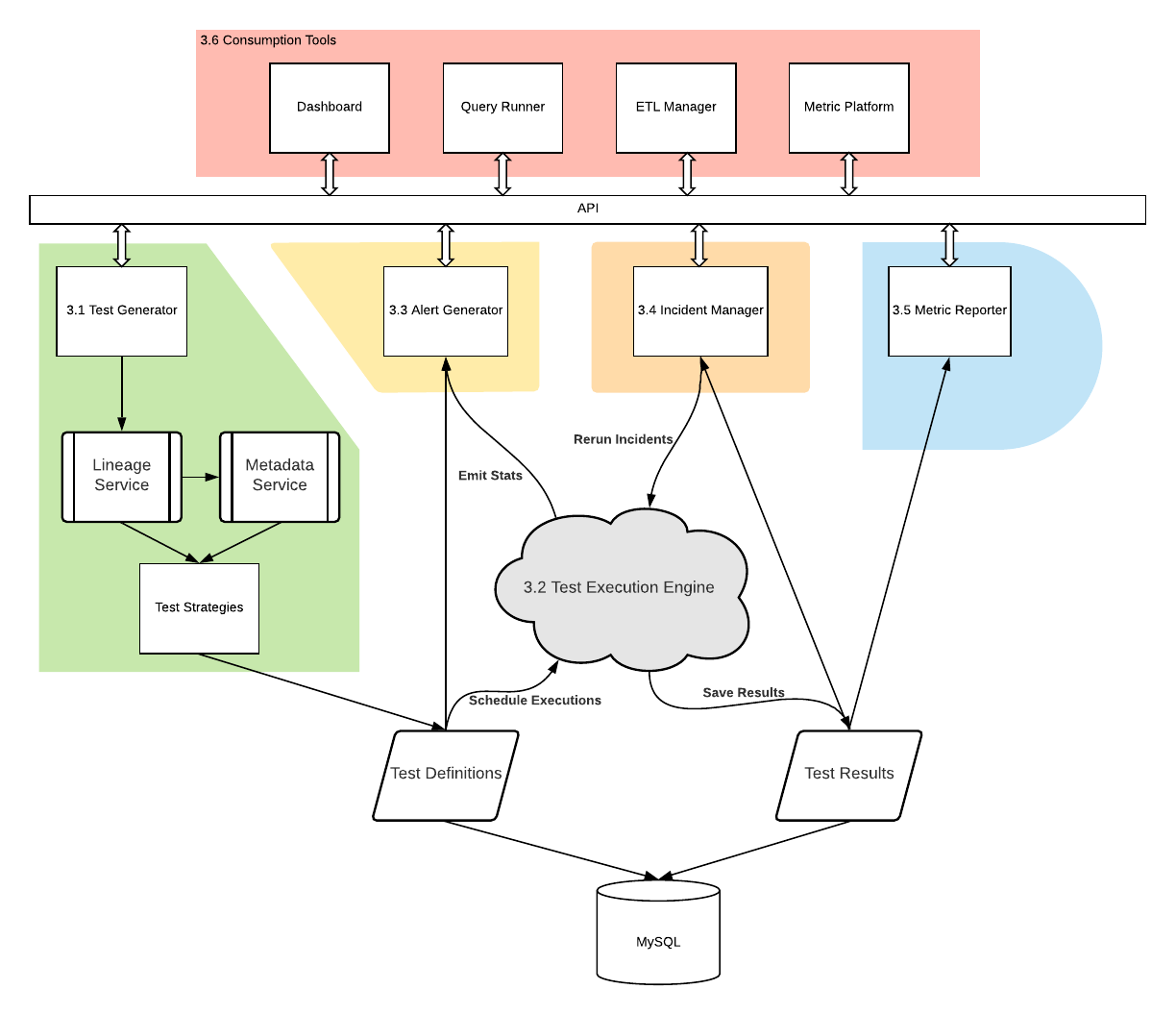
測試產生器(Test Generator)
要良好的維運數據品質,根據經驗是要盡可能減少使用者手動建立測試。測試產生器可以根據資料集的元數據自動產生標準的測試。Uber透過集中管理的元數據作為單一信任來源,這些元數據來自使用者在各種不同的存儲上建立的數據欄位。以下是一些自動建立測試會用到的數據欄位:
- SLAs:這是用來定義檢驗的閥值。所有Uber的資料都有被分級(T0是最高;T5是最低),根據分級有預設的SLA。
- 分區鍵(Partition Keys):對於大型且持續新增資料的資料表,Uber只測試最新的分區,因為靠著週期性的測試就能達成完整測試。分區鍵是從各種存儲的元數據上取得,例如Apache Hive有Metadata Store、Elasticsearch有index template。
- 排程時間:對於資料表的分區測試,需要等到一個分區完整寫完才可以執行。Uber透過新鮮度的SLA來決定分區寫完的預期時間,因此分區測試會用新鮮度的SLA來排程。
- 主鍵:有些測試必須要有主鍵,這是唯一需要使用者輸入的參數。UDQ會略過那些漏了主鍵的測試,然後發送週報提醒使用者在對應的元數據服務上設定主鍵。
除此之外,對於監控的資料表來說,使用者還會在意他的上下游資料,一旦有問題被偵測到才有辦法確認是否是上游造成的錯誤,並且通知對應的下游。UDQ當然也支援根據Lineage服務自動為所有的上下游建立測試,這就顯著提昇測試的效益也確保整個資料鏈路的品質。
但是,Lineage是動態的,因為ETL的邏輯有可能改變,隨時會有新的資料表加入以及舊的資料表淘汰。為了保持Lineage是最新的,Uber透過每日的Apache Spark任務來獲取最新的Lineage以及重新建立對應的測試來保證測試也能跟上最新的Linage。
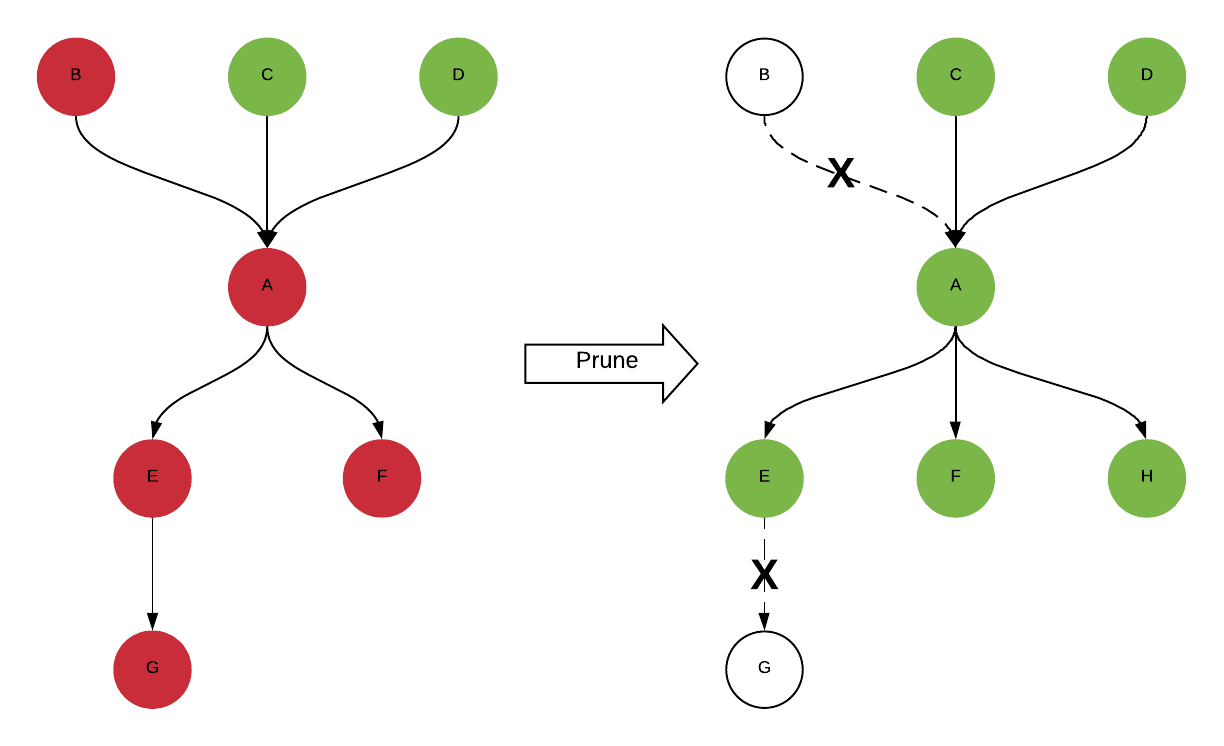
為了進一步提昇數據品質標準,Uber對上級(T0)資料集建立100%覆蓋的測試,這可以透過Push和Pull模型來達成。
- Push模型:持續取得元數據變更(資料被升降級、SLA更新等),並實時調整對應的測試。
- Pull模型:批次抓最高級的資料集和元數據來更新對應的測試。
測試執行引擎(Test Execute Engine)
執行引擎是一個基於Celery的服務,目前支援18000個測試,約需要執行100K個條件。測試可以是根據上述機制自動建立的也能是使用者客製化的,每個測試都有一個檢驗規則驗證是否滿足SLA。
測試可以是很簡單的條件,例如與一個常數比較(percentage_duplicates <= .01),也可以是一個計算過後的值。整個測試驗證的寫法是其實就是一個字串,背後有一個AST(Abstract Syntax Tree)的解析器,會把整個字串解析出來,並由測試引擎執行。
這種做法可以讓測試變得很彈性也很容易增加新的比較型態。
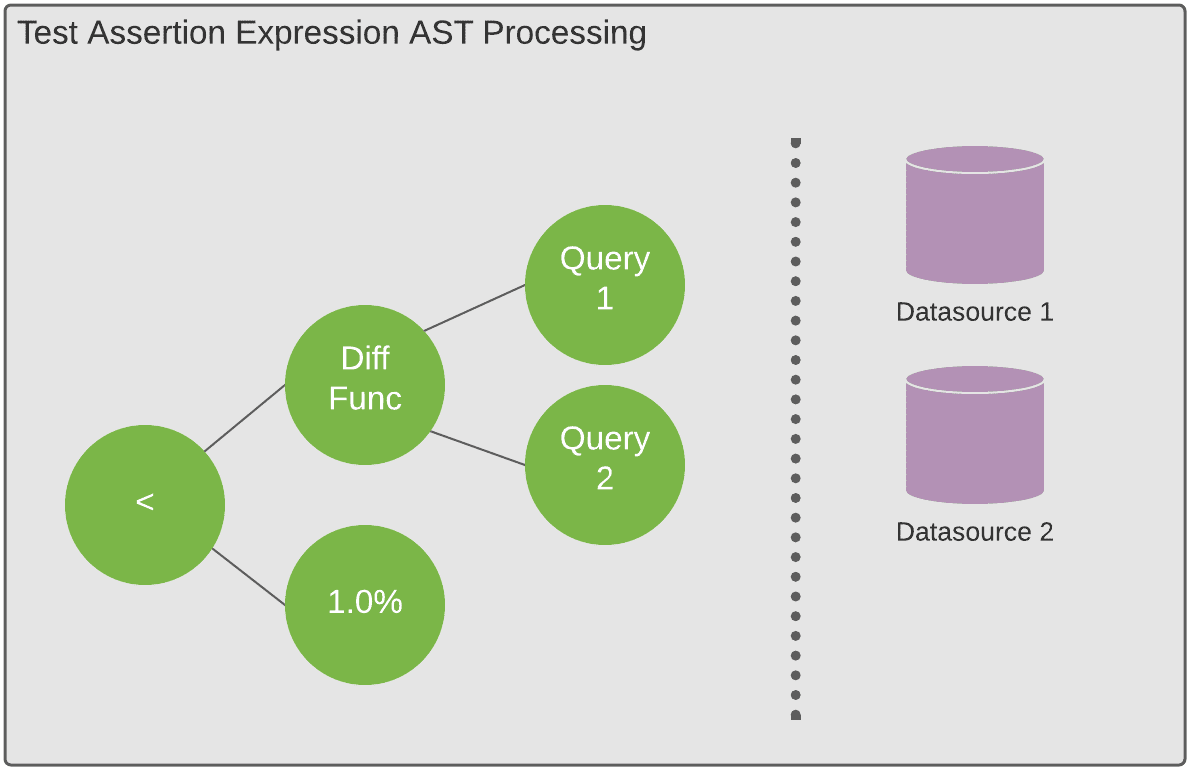
混合測試型態
混合測試會在解析AST之前有額外的計算步驟。這些額外的計算步驟需要流水線或非同步任務支援,將結果計算完後儲存起來給AST用,Uber在做跨資料庫一致性的兩種作法以及上下游測試都是基於混合測試實作的。
Bloom Filter 跨資料庫一致性
資料庫一致性比較其中一種作法是透過Bloom filter (一種機率算法,可以快速比較兩個資料集是否一致)。在每天的一致性測試中就是計算其中一個資料集的Bloom filter然後儲存下來並拿去另一個資料集進行比較,也會做一次反向比較。建立和使用Bloom filter是透過Hive的UDF,將每筆資料用Bloom filter的結果以字串形式保留,並用來比較。
用Bloom filter的一個限制是可能會誤報,因為Bloom filter並不是精準的比較只是個機率模型。但是,因為每筆資料都被建成Bloom filter的鍵值,所以在收到通報時可以知道到底哪筆資料不一致。這是一個取捨,透過各種測試的組合可以有效偵測各類特定問題。
輕量級跨資料庫一致性
這是一個比Bloom filter更輕量的作法,僅僅比較兩個資料集的資料數量,僅需要幾秒鐘就可以做完很多資料集的比較。
Uber透過兩個指令來讓測試引擎做這種驗證,第一條指令是在每個需要比較的資料集上執行,取得資料數量並儲存在MySQL;第二條指令是要測試引擎拿出所有的資料量並進行一次性比較,並產生報告。
取樣性測試
取樣性測試是一種完整性測試,隨機從上游資料集取得一些資料,並確認是否有存在在下游資料集。這是為了那些不存在在Apache Hadoop的資料集設計的,當執行取樣性測試,測試引擎會從上游抓出資料並ETL進Hive,接著拿去和下游資料集比對。
告警產生器(Alert Generator)
就像數據品質測試是自動產生的,告警也是根據模版或商業邏輯自動產生的。有一些需要的額外資訊,例如:資料表擁有者、email等資訊會放在Metadata服務。終極目標是希望做到T0等級的資料都有100%的告警覆蓋,測試建立的流程就跟上面說的一樣,但是還有些額外工作,例如:避免誤報以及維持一個統一的使用者體驗。
首先要問一個問題,所有失敗的測試都是真正失敗的嗎?以下圖為例,1:00 AM看起來只是暫時性的失敗。為了避免告警頻繁被觸發,Uber定義了一個週期,要失敗超過週期才會真正觸發告警,以下圖來說,週期是四小時,所以要連續失敗四次才會發出告警,也就是8-9 AM。
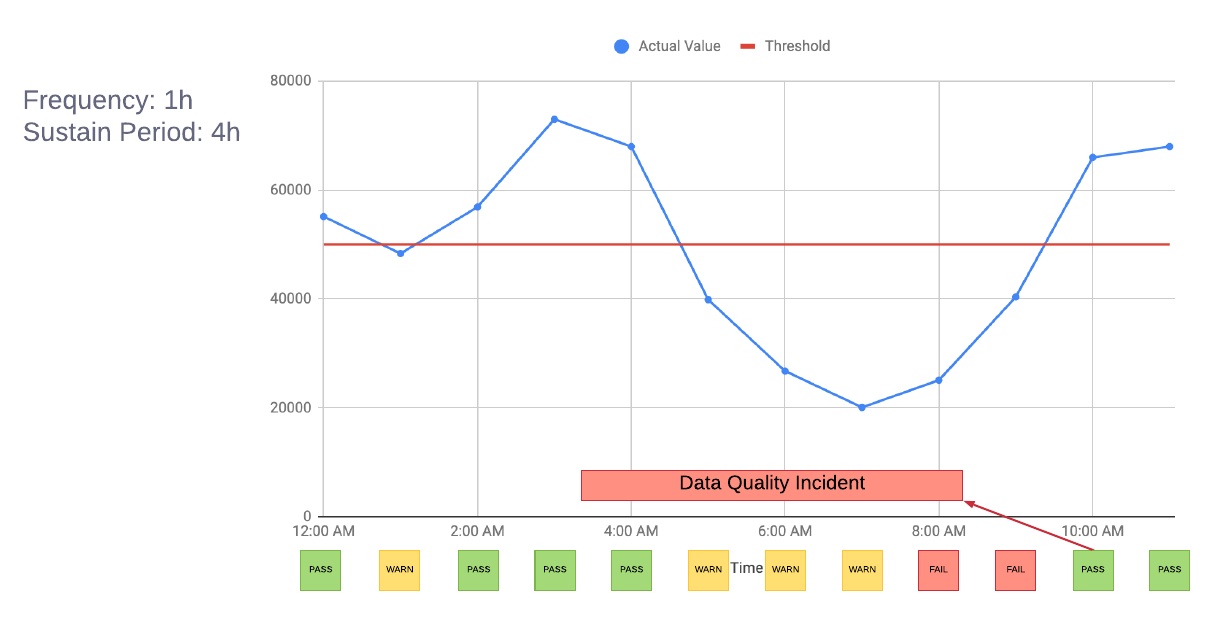
即便是真的告警,Uber也想限制告警次數來避免過度影響使用者。例如新鮮度測試極有可能與完整性測試一同出現,當資料管線延遲那就既會收到新鮮度的告警同時也會收到完整性的告警,那就應該告警一次。因此,Uber將新鮮度測試的告警作為最優先,若是新鮮度告警了,那麼別的種類的告警就可以不用送。
另外還有一個優化,UDQ有一個灰色週期的機制,可以讓剛上線的測試規則不會發出真的告警,讓使用者有機會能夠修復已知問題。
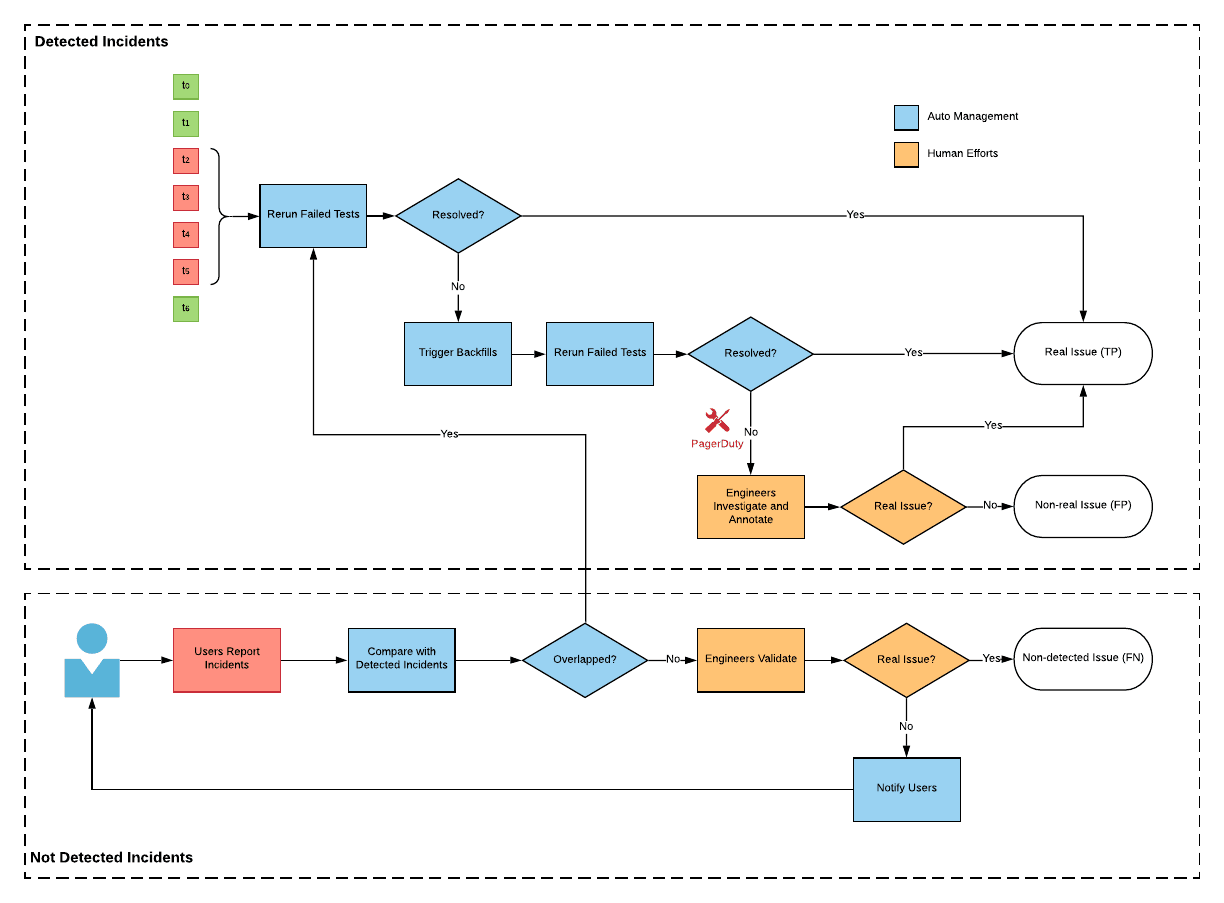
意外管理者(Incident Manager)
意外管理者是另一個重要的元件,用來分類告警。
當使用者收到告警後,使用者把問題解決掉,要怎麼讓系統知道問題已經處理好了?讓使用者輸入嗎?這不是個好作法,一來這會增加使用者負擔,二來這樣的作法不夠可靠。因此,意外管理者會週期性的重試那些錯誤的測試案例,這樣就可以在不影響使用者的情況下偵測到問題已被修復。
除了自動排程的重試,UDQ還提供使用者一個能夠手動註記並觸發重試的機制,這有以下幾種使用情境:
- 當使用者想馬上解決一個告警而不想等下次的自動觸發
- 若是測試設定錯誤之類的誤報,使用者需要能夠讓他強制解決
- Uber鼓勵使用者在註記系統上留下一些資訊通知下游或是留作未來分析的紀錄
雖然有自動化測試,但無法保證能夠偵測到所有的意外,因此意外管理者也能夠讓使用者主動回報問題,意外管理者會與已經偵測到的問題比對確認是不是新的。最終,整個系統整合自動偵測與人工回報,使數據品質能覆蓋更多面向。
指標回報器(Metric Reporter)和呈現工具(Consumption Tools)
能夠進行自動化測試後接著就是評量測試的成效和呈現數據品質的結果,因此指標回報器會量測成功和失敗的測試案例,並給出具體的評分。而呈現工具則會在儀表板上呈現各種測試的結果以及以圖形化的方式展示資料集的品質。
除此之外還有一些元件可以讓使用者透過儀表板上的結果直接查詢具體的數據以釐清問題,或者將UDQ與Uber的ETL管理整合,讓ETL管理系統在察覺到即將要運行的ETL不夠有品質而直接暫停運行。

後記
這篇文章講了滿多Uber在進行數據品質量測上的實務作法,UDQ的架構雖然完整,但其實龐大到不是一般規模的公司能夠提供的。與其照本宣科一個「完美」架構,不如借鏡一些Uber實務上的作法,找出屬於自己的數據品質量測機制。