一文看懂Netflix處理hourly pipeline延遲
這篇是翻譯Netflix最近釋出的Psyberg系列文,同時也會補充一些相關的資訊。
最主要的出處是以下三篇:
- Streamlining Membership Data Engineering at Netflix with Psyberg
- Diving Deeper into Psyberg: Stateless vs Stateful Data Processing
- Psyberg: Automated end to end catch up
前情提要
Netflix的data pipeline有兩條,一條是純batch,一條是realtime,以下是超級high level架構。

Keystone:是data pipeline的自助平台,包含建制、設定、發布、監控等;MANTIS:是Netflix自研的Orchestrator,相當於特化版的Airflow。
上圖是早期架構,後來他們也讓批次的資料源接入kafka。另外在Hadoop那已經使用Apache Iceberg作為儲存媒介。
這系列文他們要處理的問題是下面那條,也就是Spark那邊怎麼處理事件延遲。
問題背景
Netflix碰到的問題是他們在帳務處理上使用batch處理,不要求即時但要求精確且完整。
通常,他們會讓hourly pipeline算之前time slot的資料,例如:7點整的job算5點(包含之前的),但即便如此依然會碰到事件延遲。
若是stateful (incremental) 的資料處理,遇到延遲就必須從延遲事件的event time算到最新處理到的時間區間。
事件延遲為什麼會發生?系統重試、網路延遲、批次處理、系統癱瘓或上游migration等都有可能。

- processing time:其實是指串流處理常用的event time,事件發生時間。
- landing time:落地時間,類似串流處理用的process time。
痛點
早期的解法有兩種:
- 固定的回算區間 (假設大部分的遲達事件都會落在這個時間區間)。但這會導致無謂的重複計算,顯著增加ETL的處理時間和計算成本。這招的擴展性也很差,很難處理資料量體不斷變大的情況。(試想:每個小時回算過去六小時)
- 增加告警,提示什麼時候有資料延遲,人為介入後卡住pipeline,手動執行backfill。這招最單純,所以也是Netflix最常用的手段,但是重算資料和找到所有對應的下游非常痛苦。(試想:你不是這個pipeline的作者)
問題情境
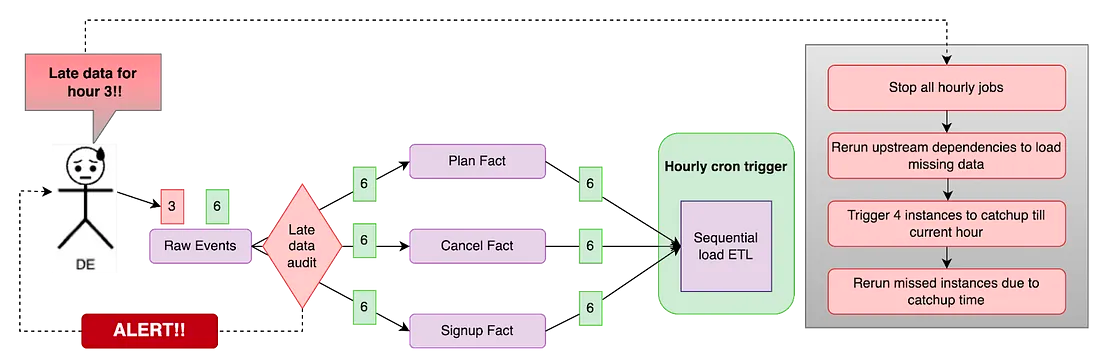
假設要處理三種事件:註冊、換方案和取消方案。有些註冊事件應該在3點發的卻延遲到了6點。系統檢測到延遲並發出告警,on-call的DE 會按照以下步驟處理。
- 查看稽核紀錄找到延遲事件以及被影響的pipeline。在這個範例中我們會知道註冊事件應該要在三點的事實表。
- 停掉所有受影響的pipeline以及下游,並將註冊事件補進事實表。
- 找出需要重跑的partition並且從那個partition跑到最新的。DE會注意到三點到六點的資料都要重跑。這個步驟很重要,因為少了註冊事件會造成接下來對應帳戶的處理都受影響。
- 現在DE花了許多時間來解決告警,那些pipeline看起來會像是有點延遲,接下來必須要發起追趕的 job 把狀態追到最新狀態(六點以後)。
純手工、耗時、加班、認知負載,簡單的說,痛苦到不行。
解法:Psyberg
Psyberg是Netflix基於Apache Iceberg開發的自動化處理框架。
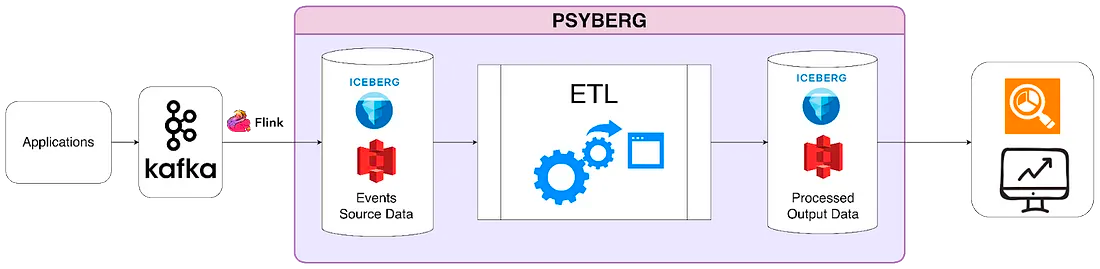
Psyberg其中一個重要的功能就是能夠偵測和管理延遲事件,這樣就可以讓pipeline不需要人工介入也能夠高效又精準的處理延遲事件。整個Psyberg是用一些自己維護的metadata以及Apache Iceberg的metadata作為骨幹來做到高效的資料處理。
快速科普一下Apache Iceberg:是一種開放資料表格式,可以被各大資料處理引擎調用,並在Object Storage上建立資料表,也就是俗稱的Data Lakehouse,如下圖。
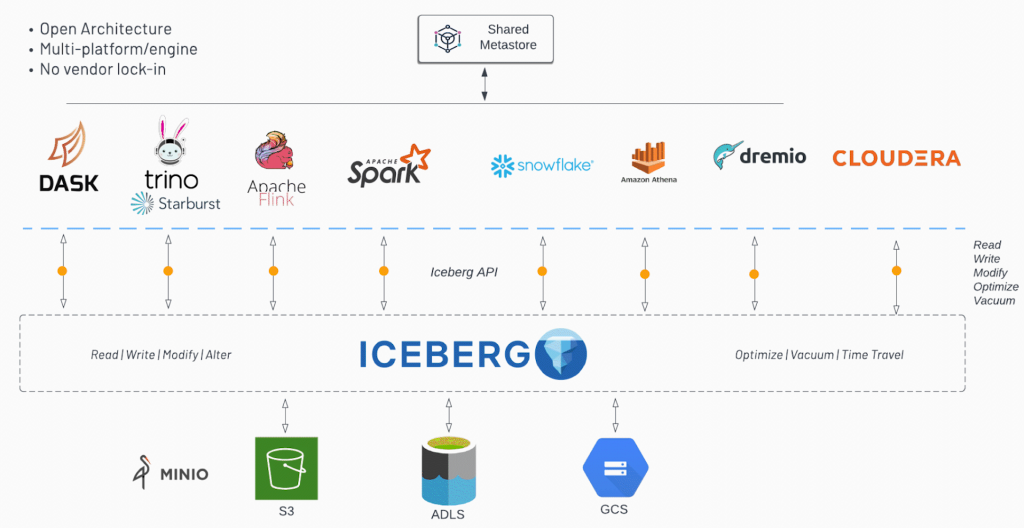
再科普一下Iceberg Metadata:因為是在Object Storage上建立表結構,所以一定需要描述檔案位置的機制,Iceberg用的是Object Storage Service上的metadata機制,一來節省存取開銷、二來減少檔案遷移。

Psyberg原理
關鍵是High Watermark的處理。
High Watermark是指pipeline最後一次更新的時間,這主要用來偵測從上一次更新後有沒有新change。
Iceberg Metadata
Iceberg有兩個重要的metadata表:snapshots和partitions。
snapshots
snapshots表紀錄基本的metadata,例如:
快照的建立時間
執行操作的種類
分區建立/更新的summary
這些細節讓Psyberg可以追蹤不同的操作並且釐清從上一次更新到現在的改變。舉例來說。

partitions
partitions表值得注意的是他儲存了以下資訊:
在資料表中分區鍵的資訊
特定分區中的分區鍵範圍

透過這兩種metadata表,將其組合成一包反序列化格式,這有助於Psyberg了解延遲事件而不用去查實際資料。
Psyberg Metadata
除了,iceberg的metadata,Psyberg還維護了自己的metadata表:session和high watermark,這兩張表都基於 job 的名稱做分區以便維護各個 job 的資訊。
session
session表維護每一個pipeline的執行狀態,包含:
Job 分區,用於追蹤pipeline的運行資訊
Session ID,每一次運行的唯一標示
處理URI,用於識別需要載入的分區
“起始日期”、“起始小時”、“結束日期”和”結束小時”,分別用於事件時間和處理時間
high watermark
high watermark表在每個pipeline運行結束後會從session表中拿出相關資料。
最新/前一次的high watermark時間戳
最新執行的metadata

這些信息對於每個 job 至關重要,因為這有助於確定要加載的數據,在處理後更新HWM,最終生成輸出信號,通知下游pipeline資料截至日期和時間,確保完整可用。同時,這也作為troubleshoot和audit用。
Stateless vs Stateful
前面敘述了Psyberg的metadata,接著要再對問題細分,有兩種處理模式:無狀態和有狀態。
理解處理資料的需求可以更了解該如何處理事件延遲。
無狀態資料處理:事件只和自身有關,不會被到達順序影響。舉例來說,我們需要追蹤全部使用者的註冊數,那麼註冊事件的順序不重要,而且註冊事件彼此是獨立的。這種情境下,只需要把資料寫入事實表就好。
有狀態資料處理:這模式是指事件依賴數個輸入串流的順序。舉例來說,顧客的生命週期會包含數個階段,例如帳號建立、方案升降級和取消,這需要確保順序是正確的,若是有延遲事件那需要將已經處理過的事件重新處理。
讓我們用一個常見的工作流程:載入資料到事實表來演示這兩個模式。

INIT階段
根據給進來的參數,Psyberg會算出正確的資料區間。
參數如下:
Stateless INIT
這邊用一個紀錄註冊事件的事實表為例,這會是每小時跑,目的是把原始的註冊事件根據(landing data, hour, batch id)做分區建表。
以下是一個YAML範例:
1 | - job: |
從參數 (etl_pattern_id=1) 可以看出來,這個 job 是stateless的。
Psyberg也根據參數找到對應的snapshots表,用summary可以取出原始表的分區資訊。
{“partitions.dateint=20230914/hour=3/batchid=1692810122580_70666”: “added-data-files=2,added-records=24,added-files-size=29839”}
這些資訊解析完會記錄在 psyberg_session_f 表提供給 LOAD.FACT_TABLE 這階段使用。
Stateful INIT
若是事件有順序相依,那就需要用有狀態的事件處理。
我們用建立一個 cancel 的事實表作為例子,這張表需要兩個上游:
cancel 事件流,這表示使用者發出取消
儲存了所有使用者請求的事實表,這用來在帳單結算週期前取消訂閱
這些上游可以用來分析這些 churn 是自願還非自願。
這也用類似上述的YAML,但有一些差別。
1 | - job: |
因為是 etl_pattern_id=2 所以表示是stateful。
重要的是 src_tables 這項,這列出源事件流 raw_cancels,另外 processing_ts 表示是事件時間。這和另一個選項 event_landing_ts 的用途不同。
透過捕捉 raw_cancels 和 cancel_request_fact 以及指定 processing_ts 可以釐清到底哪些事件遲到。
和前述的stateless處理一樣,從參數中找出對應的分區資訊並轉成以下格式。

來源是partitions表,會列出 event_processing_ts 的 min 和 max 以及 event_landing_ts 的 min 和 max。
VTTS = Valid To TimeStamp
有了 processing_ts 的 min 就可以找出遲達事件在哪以及要從哪個分區開始重跑。

1694704259000是UTC Sep. 14, 2023 15:10:59
另外,也可以從所有上游的VTTS找出要重跑的上限在哪。

Psyberg透過這些metadata計算就可以知道該怎麼自動處理事件了,這些結果會存進 psyberg_session_f。
WAP階段 (Write Audit Publish)
快速科普一下WAP,WAP是Iceberg的一種設計模式。因為Iceberg可以寫入資料但不公開 (目的一樣是為了減少Object Storage的存取),所以可以先由pipeline把資料寫入,然後發起驗證流程,確認沒問題再公開資料。
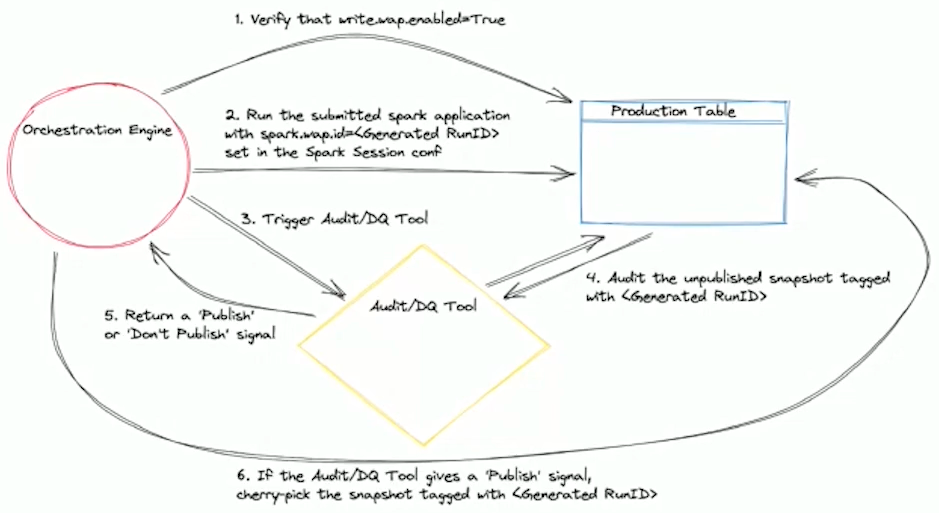
當Iceberg snapshot還沒寫入時會先做驗證。在 LOAD.FACT_TABLE 會用 psyberg_session_id 和 process_name 做為參數。
對於 stateless,要處理的URI會從 psyberg_session_f 讀出來,所有商業邏輯的處理以及延遲事件的處理都會在這時候解決,但這些不會直接寫入,而是會先落到uncommit snapshot (WAP pattern)。
同理,stateful也是類似的流程,只是多了計算回算區間的判斷,透過這些機制就可以由Psyberg自動處理了。
Audit階段
在那些未發布快照上會運行很多確認流程,透過Psyberg的metadata就可以有效辨識正確性和完整性的問題,當審核完成,這些資料就會被發佈到目標表。
HWM Commit階段
藉由Psyberg metadata,我們可以找出最新
利用Psyberg metadata,我們可以找出Iceberg snapshots相關的最新時間戳。這個時間戳用於更新 high watermark表,有了新的HWM,這樣後續的pipeline就可以找出新的資料變更。
具體例子

以上是一個用戶的生命週期,我們要追蹤每個小時用戶的帳號狀態,例如啟用、升級、降級、取消。
作法:
建立兩張無狀態事實表:註冊、帳戶方案。
建立一張有狀態事實表:取消。
建立一張有狀態維度表:每小時讀取上面三張事實表,並產出帳戶狀態。
對於無狀態表,就是有新事件就append;而有狀態表則是overwrite。
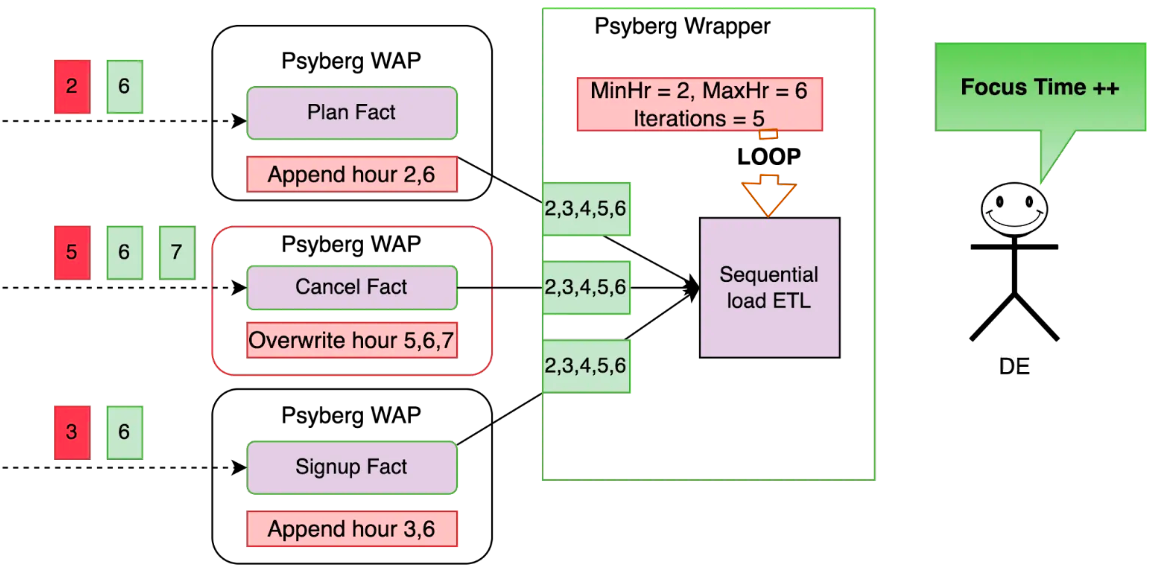
假設:所有的事實表都已經處理到第5小時,之前的事件都表示延遲事件 (上圖紅2, 5, 3)。
事實表的部分:
對於計畫表和註冊表,因為是無狀態,所以直接把 [2, 6] 和 [3, 6] 附加在對應的事實表即可。
對於取消表,因為是有狀態,所以 [5, 6, 7] 都會覆寫對應的資料。
這種基於固定時間窗口的做法可以有效減少資料處理的量。
維度表的部分:
根據之前介紹的算法可以得到需要回算的區間是 2-6,所以維度表需要重算 2-6 小時的資料。
回算目標時間區間的分區表並寫入目標表,這會最小化不必要的重新處理。
這樣Psyberg可以在沒有人為介入的情況下自動追上資料。
Psyberg帶來的優點
使用的計算資源大幅下降,core Spark少了90%。
更好的可靠度和精確度,自從Psyberg做完,我們沒再做過手工也沒再丟失資料。
有了固定模版,要做到類似的pipeline更加容易。